CVS annotation app
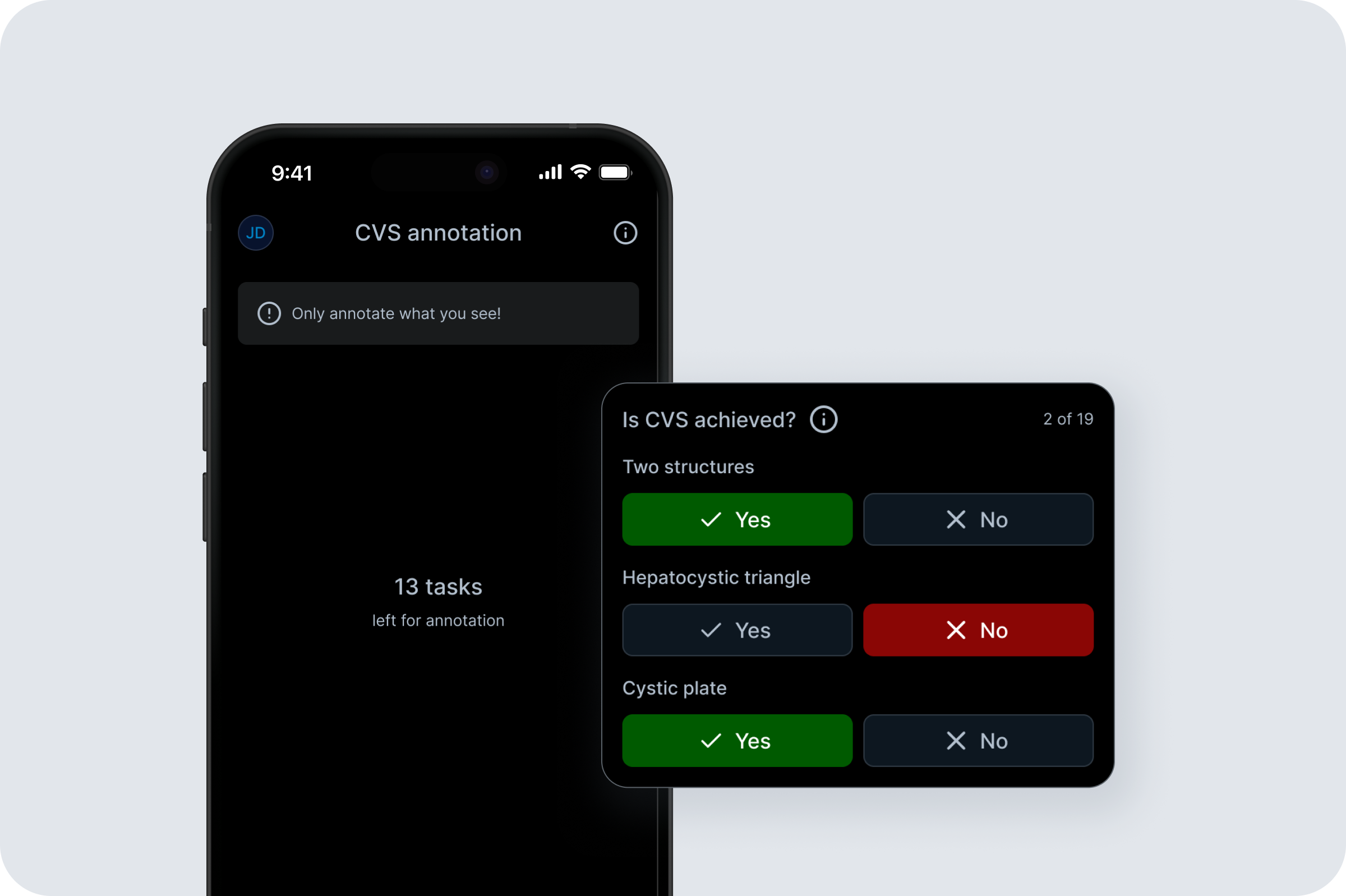
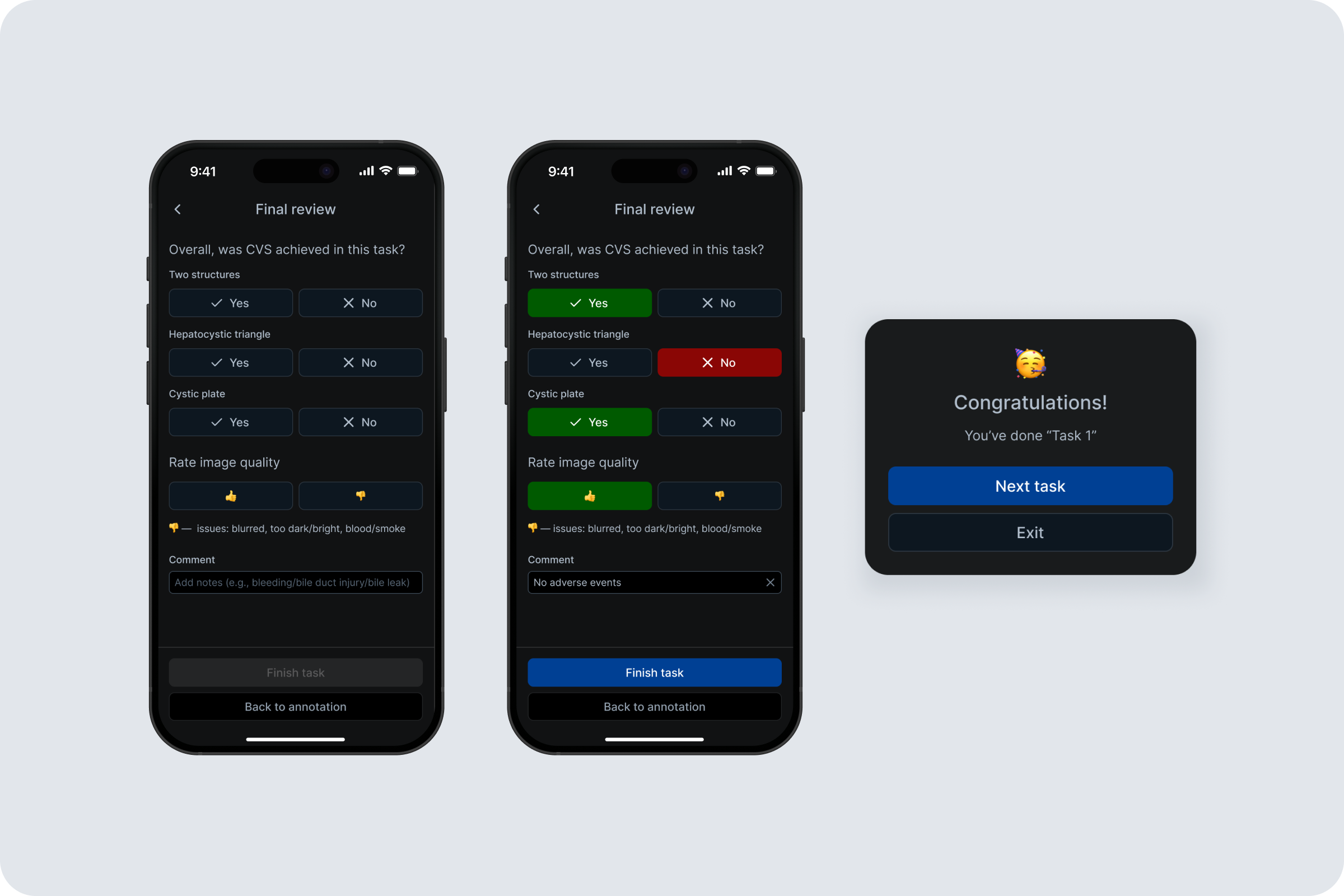
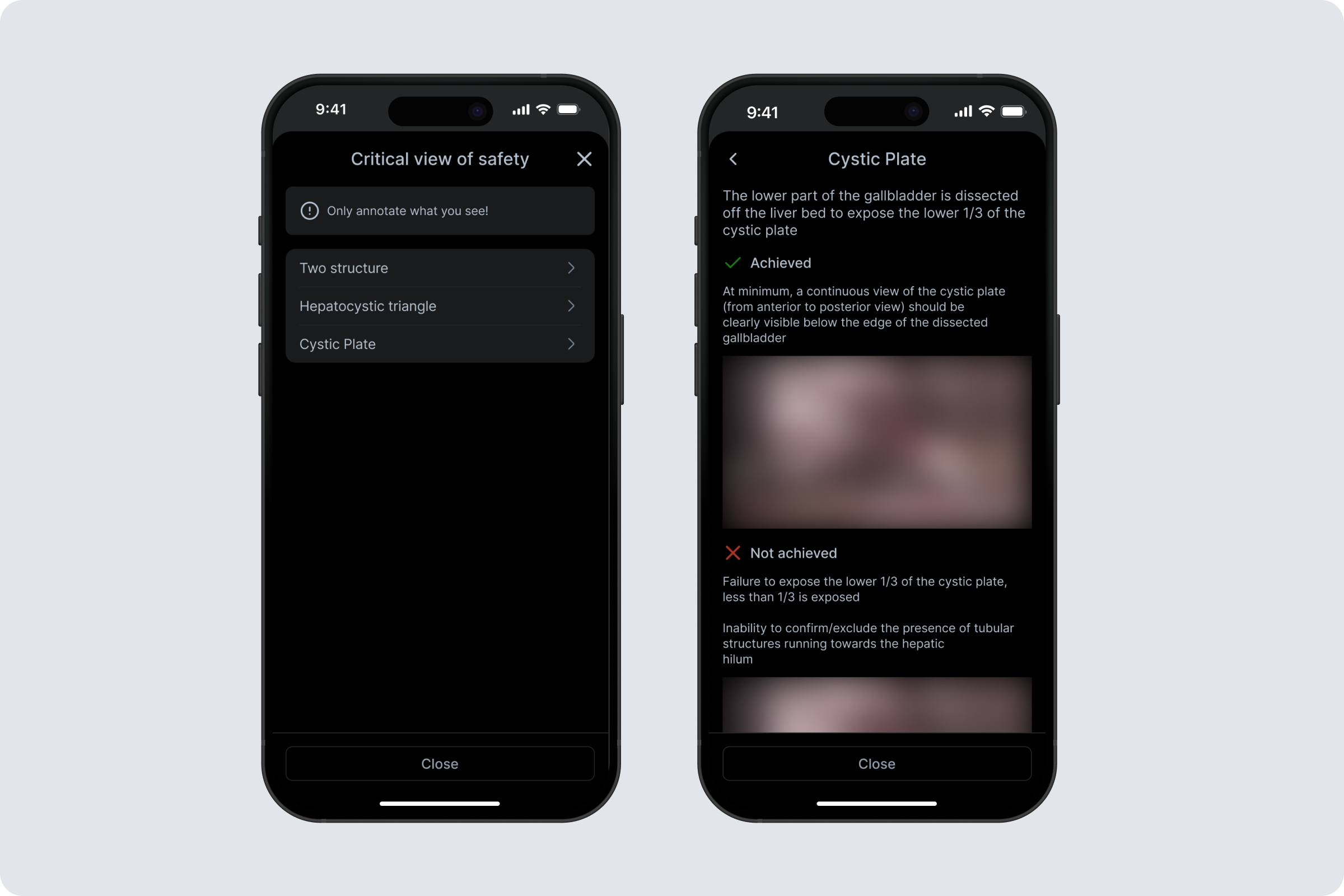
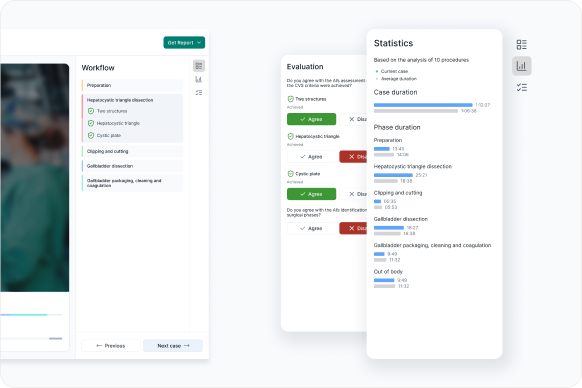
CVS Annotation App is a cross-platform tool for labeling Critical View of Safety (CVS) criteria in laparoscopic cholecystectomy frames to generate training data for an ML model. As a Product Designer, I led the end-to-end design from MVP to iteration. My role was to translate clinical labeling needs and technical constraints into a simple, reliable workflow for surgeons. Key responsibilities included defining the annotation flow, designing Flutter-friendly UI patterns and states, running surgeon interviews, synthesizing feedback, and iterating from video-based tasks to an image-first experience with per-task comments and visual hint references for each criterion.
Role
Product Designer (Solo)
Work type
New product (0→1)
Team
Product Manager, Flutter and Backend developers, QA
Contribution
Product discovery, User experience, Mobile app design, User interviews